昨天學習了一些基本概念
今天要來看python 實作
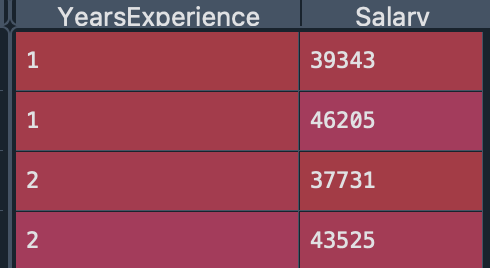
再進入線性回歸之前, 我們需要對資料做前處理
這裡用的是之前範本裡的code
dataset = pd.read_csv('Salary_Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 1].values
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=1/3, random_state=0)
我們使用的是sklearn.linear_model 裡的 LinearRegression class
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(x_train, y_train)
y_pred = regressor.predict(x_test)
是時候驗收成果了
這時候可以用Vairable Explorer 看到 y_pred 和 y_test 的資料
看看機器預測的結果跟實際結果差多少
可以發現大部分預測都還算成功, 但仍有資料(ex: 第七筆)有誤差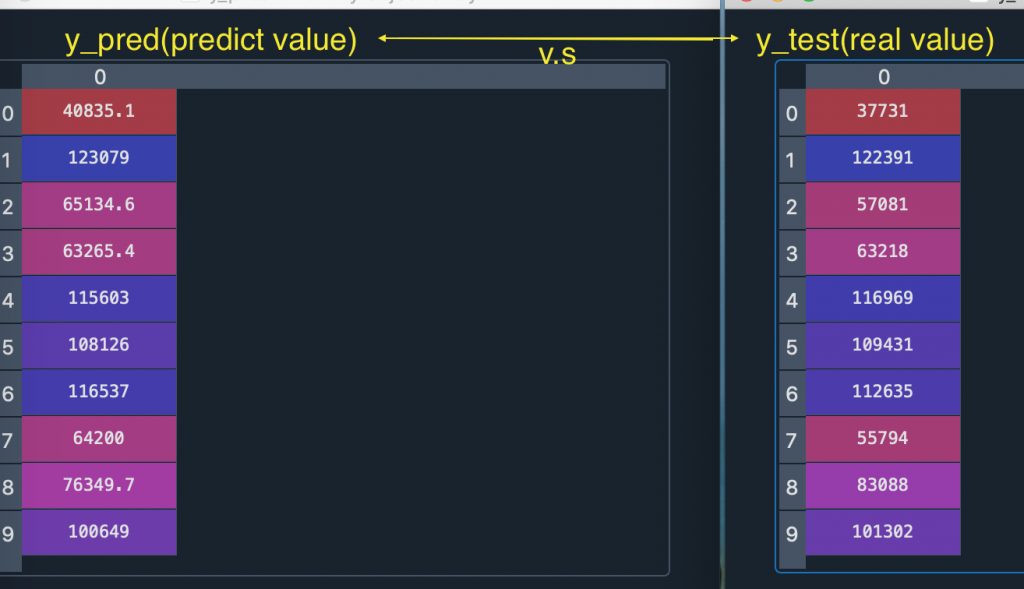
只看數據沒有感覺, 我們可以把model 最重要的線給畫出來
這裡會畫兩張圖, 不過方法都是一樣的, 我以第一張圖來說明function
第二張圖預計呈現的是 testing data 和 model 的差異
因此散點帶入testing data(當作答案)
直線則用 x_train 和 regressor predict 出的y值來畫
注意:第二張圖的plot()跟第一張帶一樣的參數, 原因是
regressor 是套用x_train 跟 y_train 來訓練model
因此不管是用predict(x_train) or predict(x_test) 都會得到一樣的線
因為背後都是同一個regressor
import matplotlib.pyplot as plt
plt.scatter(x_train, y_train, color = 'red')
plt.plot(x_train, regressor.predict(x_train), color = 'blue')
plt.title("Salary v.s Experience (training set)")
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()
plt.scatter(x_test, y_test, color = 'red')
plt.plot(x_train, regressor.predict(x_train), color = 'blue')
plt.title("Salary v.s Experience (testing set)")
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()
第一張表達的是training data set 和 model 的關係
可以看到大部分的資料跟model 都很接近, 不過仍然有一些點有誤差
第二張圖是testing data set 和model 的關係
紅色點的y軸是機器預測值, 跟model 也相當接近
# -*- coding: utf-8 -*-
"""
Editor: Ironcat45
Date: 2022/09/23
"""
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
"""
1. <Data preprocessing>
1. load the Salary_Data.csv
2. read the "experience" column as x
read the "salary" column as y
3. split the data to the trainset(2/3) and testset(1/3)
"""
dataset = pd.read_csv('Salary_Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 1].values
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=1/3, random_state=0)
"""
2. <Linear regression>
Fitting simple linear regression to the training set
1. create an LinearRegression obj named regressor
2. fit the x_train and y_train data(so now the regression is done)
3. note that we don't have to deal with feature scaling since
the class LinearRegression contains this step automatically
"""
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(x_train, y_train)
"""
3. <Linear regression>
Predicting the test set results
"""
y_pred = regressor.predict(x_test)
"""
4. Visualising the training set results
"""
import matplotlib.pyplot as plt
plt.scatter(x_train, y_train, color = 'red')
plt.plot(x_train, regressor.predict(x_train), color = 'blue')
plt.title("Salary v.s Experience (training set)")
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()
plt.scatter(x_test, y_test, color = 'red')
plt.plot(x_train, regressor.predict(x_train), color = 'blue')
plt.title("Salary v.s Experience (testing set)")
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()


 iThome鐵人賽
iThome鐵人賽